When an LLM reasons about a dataset, it starts from scratch. It writes code to explore the table, fits a quick model or computes correlations, interprets the output, and builds up an understanding of the data's structure, all within a single conversation. The next time someone asks a question about the same dataset, all of that scaffolding is gone. The model rebuilds it again, possibly differently.
This naive approach may be acceptable for straightforward questions. Compute a correlation matrix, find missing values, plot a distribution, etc. These are one-shot tasks where code is an acceptable answer. But there are harder analytical questions: which features interact, where a relationship changes direction, which column is structurally anomalous. These depend on understanding the data deeply and building up to an answer via intermediate steps. For these, rebuilding from scratch is unreliable, expensive, and often inadequate.
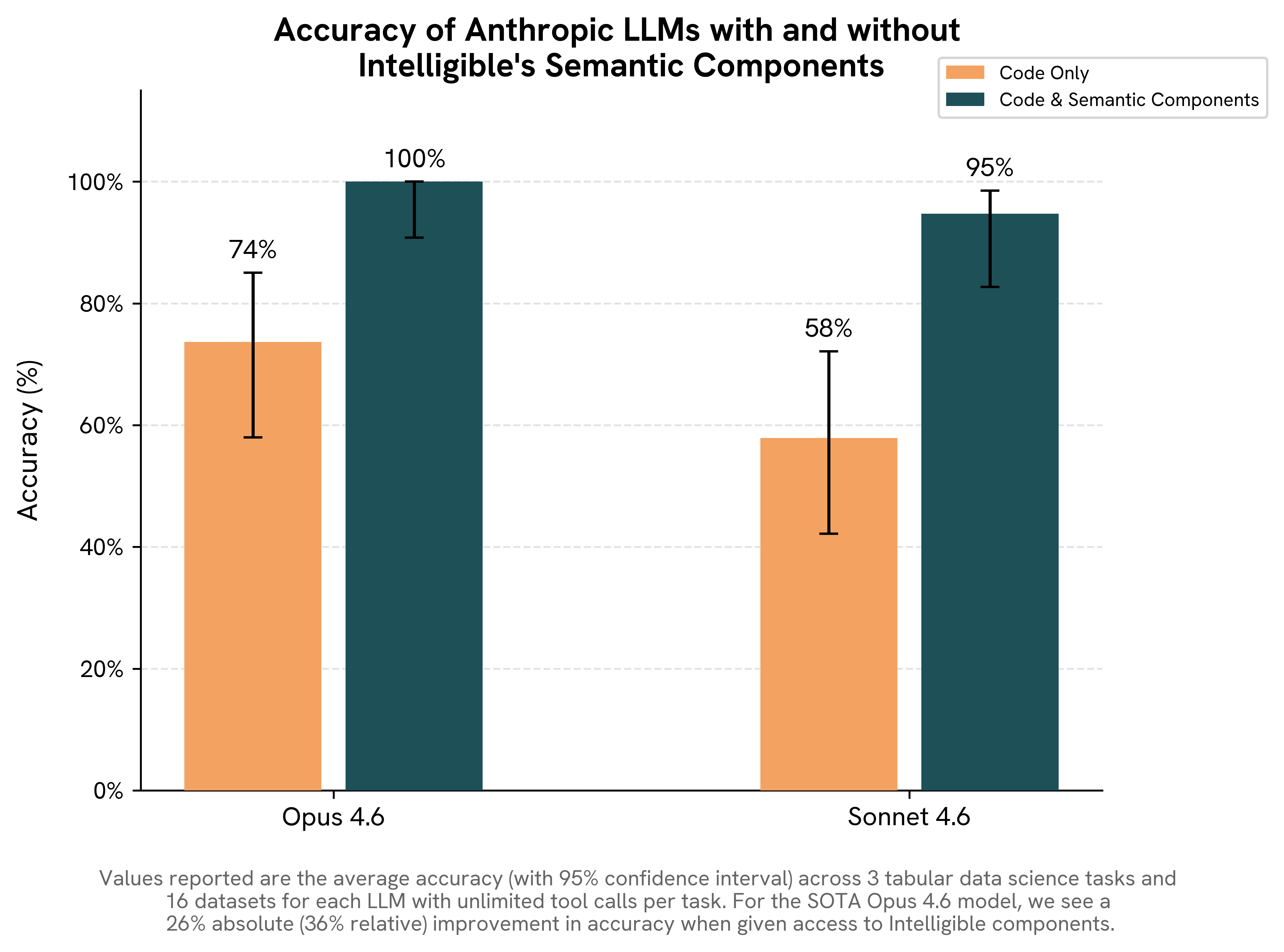
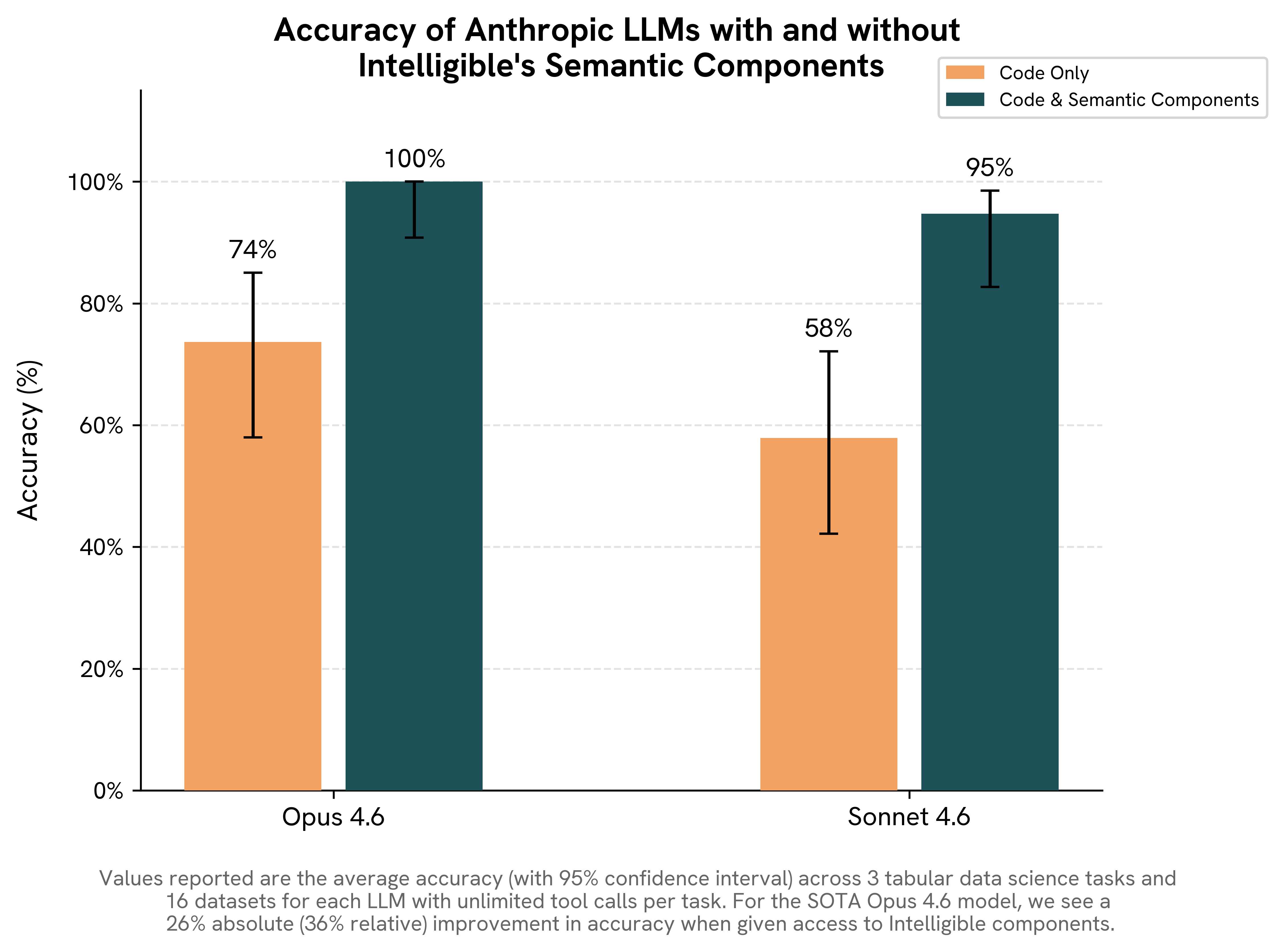
We evaluated this by presenting frontier LLMs with three analytical tasks under two conditions — with and without access to pre-computed structural knowledge — and measured how much that knowledge changed the accuracy of their answers.
Setup
We gave the model a dataset, a Python sandbox, and an unlimited tool call budget, then asked it an analytical question. Each task runs in two conditions:
- Code-only: The model can write and execute Python against the dataset. To assist the model, we pre-loaded the dataset into a Pandas dataframe in the Python sandbox.
- Code + semantic components: The model also has access to pre-computed components (e.g. column summary statistics, feature importances, shape functions, pairwise interactions and interaction rankings from an Explainable Boosting Machine trained on the dataset). These components are automatically generated using Intelligible's intelligible-ai package and exposed to the model as callable tools — for example, get_feature_importances or get_interaction_rankings — that the model can invoke alongside its Python sandbox during the conversation.
The only variable across these two settings is whether pre-computed structural knowledge is available.
Within each of these two settings, we evaluated Claude Opus 4.6 and Claude Sonnet 4.6 across four base tabular datasets [1, 2, 3, 4] at multiple row counts (100, 500, 1,000, and 10,000). To avoid contamination from LLM training data, we constructed evaluation tasks by injecting a synthetic phenomenon (e.g., corrupted rows or artificial interactions) into a dataset. This ensured that the ground-truth answer (i.e., recovery of the injected phenomenon) was known, unambiguous, and unseen during training. In total, this procedure yielded 48 candidate tasks, of which 10 were excluded because the injected phenomenon was not sufficiently strong (e.g., an injected pairwise interaction did not rank as the strongest in the dataset), leaving 38 tasks for evaluation.
Task 1: Data quality detection with obfuscated columns
Task: A Boolean flag column marks problematic rows. Identify it. All column names are random strings.
Why we care: In enterprise datasets, training on anomalous data silently degrades model performance. Identifying rules to exclude problematic rows is a routine but time-consuming part of data cleaning. Any AI system that is designed to deploy predictive models should first check for data quality.
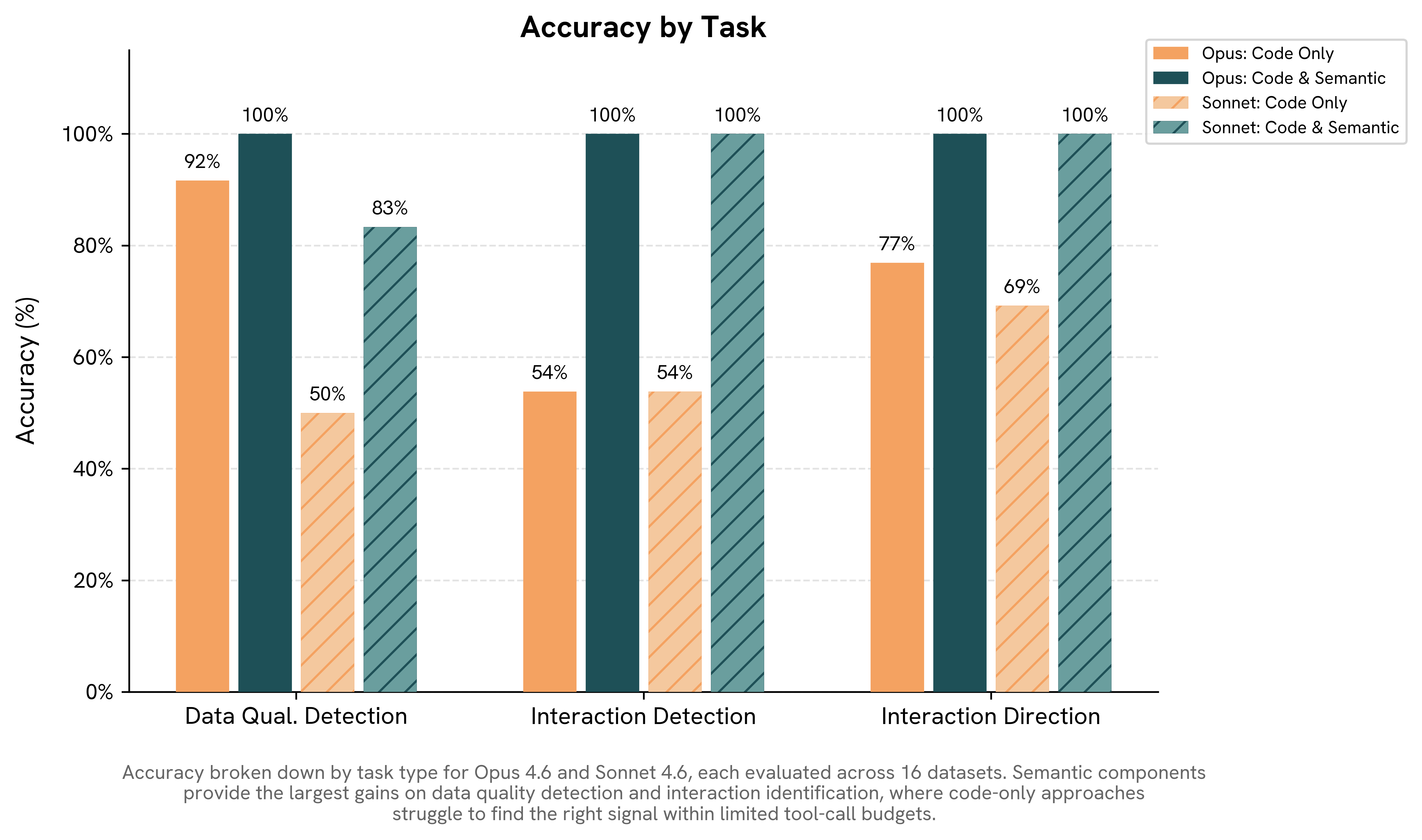
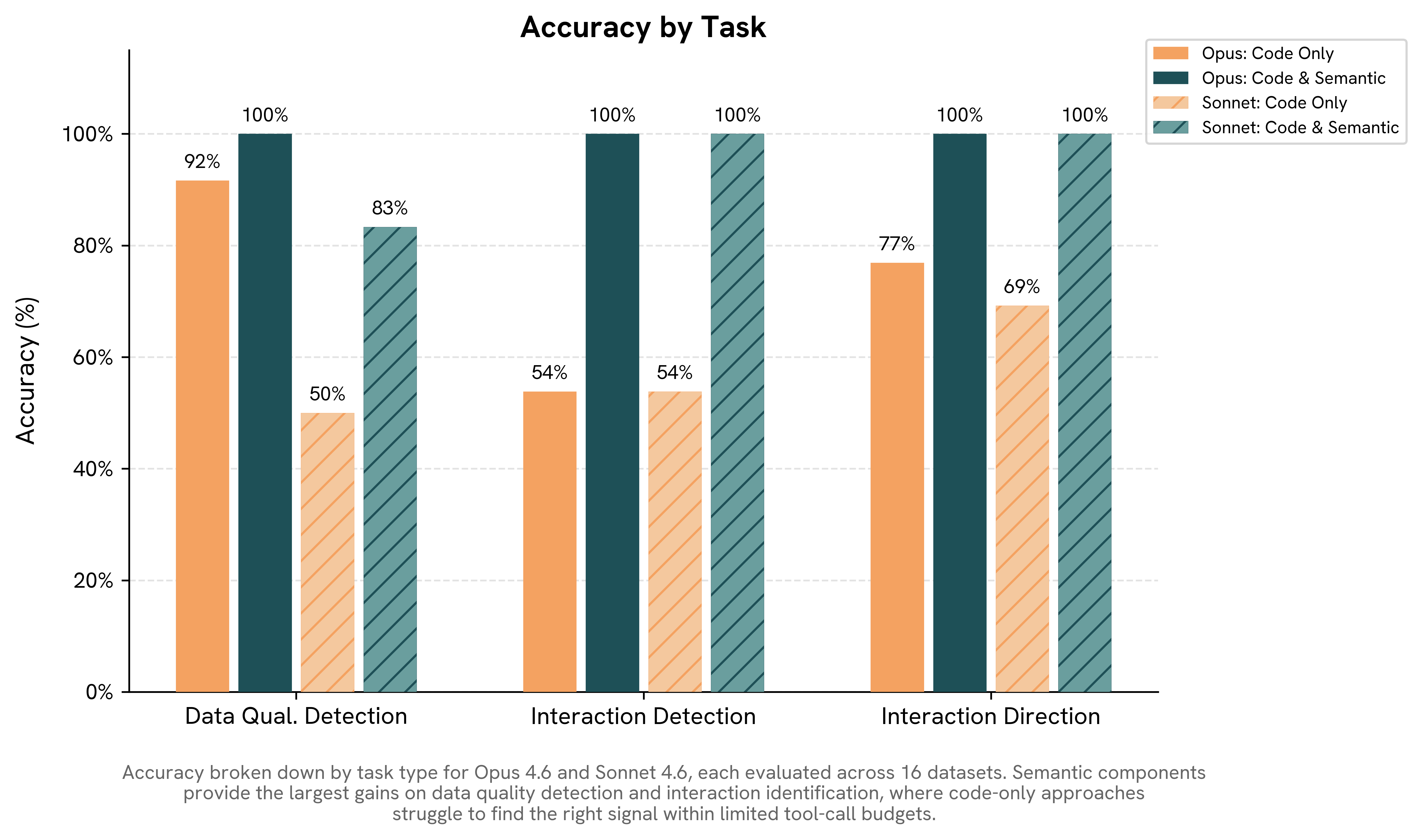
Results: Code-only accuracy (both models combined): 71%. With semantic components: 92%. Opus: 92% → 100%. Sonnet: 50% → 83%
For this task, we additionally obfuscate all column names with random strings. Frontier models have memorized popular tabular datasets. If you ask Claude about bike sharing data, it will recall column names and known quirks. Obfuscation ensures we’re measuring reasoning rather than recall.
In code-only mode, the model explores ~20 opaque columns looking for the one that flags bad rows. It has no structural prior, so it falls back on heuristics: checking for missing values, high correlations, distribution anomalies.
In contrast, when given Intelligible's semantic components, LLMs quickly identify the column that flags data quality problems. They do so by exploiting a nonobvious characteristic: data quality can be understood as an interaction effect, where a data quality indicator modulates the predictive relationship. In this task the indicator is a Boolean column in the dataset, so its two values produce clear differentials that surface as strong interaction effects.
Armed with semantic components, the LLM follows a streamlined procedure. Opus, for example, typically needs just 4–6 calls: retrieve feature importances, examine the shape function of the top binary column, and confirm the result with a Python check.
Task 2: Interaction detection
Task: Which pair of features has the strongest interaction effect on the outcome?
Why we care: As the previous task showed, data quality problems can hide inside interaction effects. They're not the only thing hiding there—so do subgroup-specific risks, conditional treatment responses, and failure modes that only emerge when two conditions coincide. These patterns are invisible to linear methods, and they're exactly the patterns that drive costly surprises in production.
Results: Code-only accuracy: 54%. With semantic components: 100%. Both Opus and Sonnet went 54% → 100%.
Identifying interactions from scratch requires searching over all feature pairs, fitting interaction terms, computing H-statistics, or estimating SHAP values. These methods can find the right answer but also frequently disagree with the actual nonlinear interaction structure. Without a solid foundation to build on, LLMs identify the wrong pair on nearly half of instances, and different statistical methods produce different wrong answers.
With semantic components, every single instance is solved in a single tool call. The LLM retrieves pairwise interaction rankings, reads the top-ranked pair, and answers. No Python needed.
Task 3: Interaction direction
Task: For the strongest interacting feature pair: when the first feature (sorted alphabetically) is above its median, does increasing the second feature increase or decrease the outcome?
Why we care: Knowing that two features interact is only half the picture. The direction determines whether the relationship is synergistic or antagonistic, and getting the direction wrong can invert a recommendation entirely.
Results: Code-only accuracy: 73%. With semantic components: 100%. Opus: 77% → 100%. Sonnet: 69% → 100%. Comparing accuracies against Task 2 is misleading because this task is a binary question, so random guessing scores 50%.
This task is a two-step problem: first identify the pair, then determine the direction. Code-only LLMs mostly fail on step one because they try to avoid the difficulty. Instead of exerting effort and employing complicated statistical tools to find the correct interaction pair, code-only LLMs use linear regression interaction terms, which leads to incorrect rankings and hence incorrect answers.
With the semantic components, the harder subproblem (pair identification via retrieving interaction rankings) is precomputed and available as a tool call. Hence, the LLM focuses its Python code on what’s actually being asked: computing the conditional correlation. The typical pattern is 3 semantic calls (interaction rankings, dataset overview, interaction surface), followed by 2 Python calls (compute median, check direction). Five total calls, high accuracy.
The full picture
The pattern across these three tasks is consistent: when an analytical question depends on structural knowledge about the dataset, providing that knowledge as a pre-computed resource produces large accuracy gains.
On one hand, this is obvious—giving a model more information should make it better at reasoning. On the other hand, it's surprising. None of the structural knowledge in these experiments was external to the datasets. Every answer was self-contained, derivable through statistical analysis of the data itself. We gave the LLMs an unlimited budget for Python calls. We weren't measuring efficiency; we were measuring accuracy. And yet, LLMs with Python sandboxes regularly got the wrong answer. Pre-computed semantic components produced major gains on questions the models could, in principle, have answered on their own.
Reliable AI reasoning requires a foundation: persistent, precomputed knowledge about the data itself. This is what we're building at Intelligible. Our system extracts structural knowledge from enterprise data using interpretable models, persists it, and makes it available to LLMs and AI systems as an interactive semantic layer. The premise is straightforward: data meaning should be infrastructure, computed once and maintained, not regenerated from scratch on every query.
These three tasks are a starting point. We're working on a full benchmark and associated tooling for evaluating grounded enterprise reasoning. If you're building in this space, let’s talk.